Zangwei Zheng, zangwei@u.nus.edu
National University of Singapore
ACL 2023 Outstanding Paper Award
Other version: [arXiv] [Code] [中文]
Discuss on X with the author.
TL;DR
Training large language models (LLMs) uses a lot of memory. CAME cuts memory use to Adafactor levels but keeps Adam-like performance.
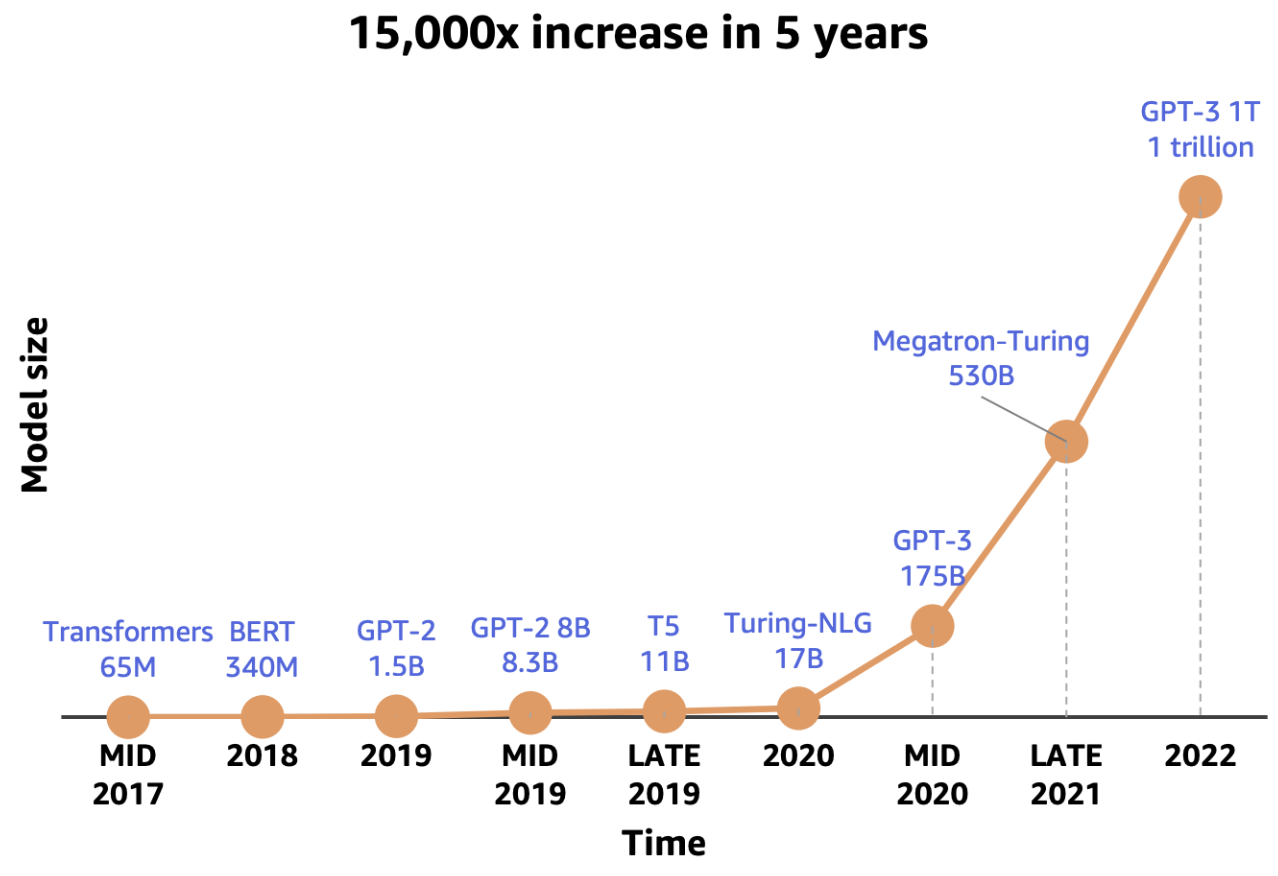
LLM training needs a lot of memory
As LLMs grow, training them requires more memory. A big part of that memory goes to the optimizer, not just the model weights. For example, Adam needs about six times more memory than the model itself in mixed-precision training because it stores the m and v states plus fp32 copies.
One way to save memory is to shrink the optimizer states. Adafactor, widely used at Google, does this by decomposing the second-moment state v:
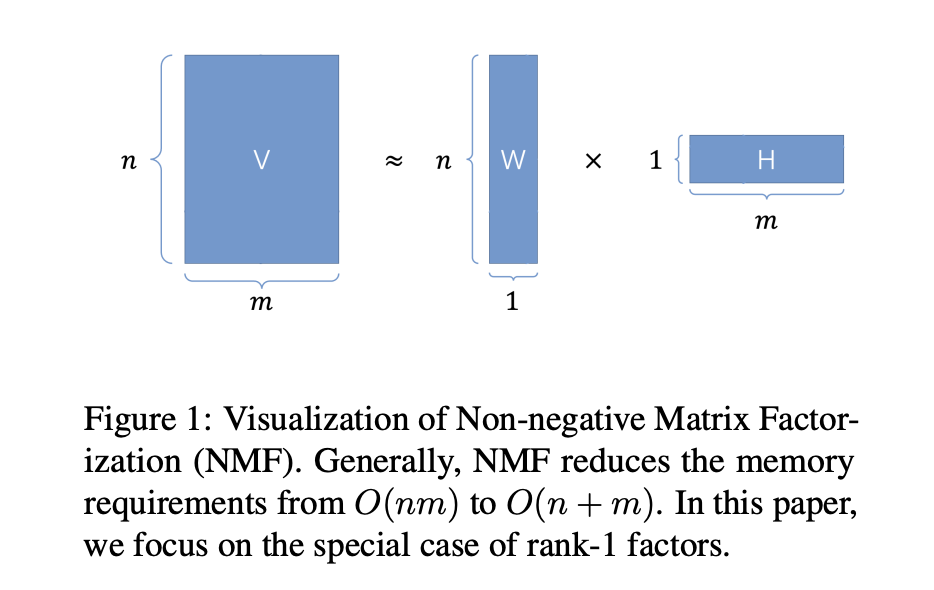
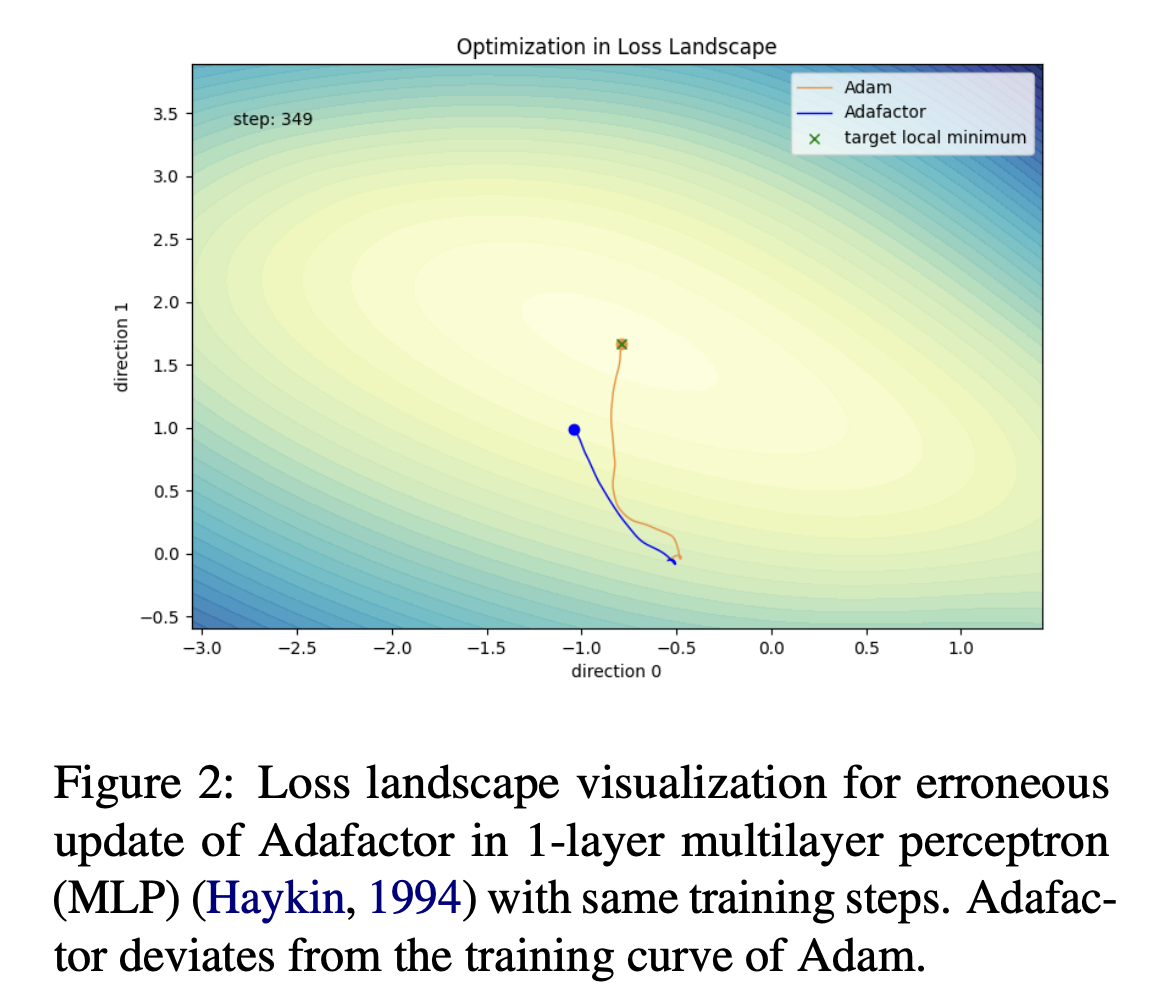
This reduces memory from O(nm) to O(n+m), which is much cheaper. However, the decomposition can make updates unstable and hurt performance in large-scale pretraining. In a simple 1-layer MLP example, Adafactor drifts away from Adam’s training curve.
Confidence-guided Adaptive Memory Efficient Optimization (CAME)
To fix Adafactor’s instability, we propose CAME. CAME adds a confidence-based correction to the update size and then factorizes the confidence matrix with non‑negative matrix factorization, so it does not add much memory. In the algorithm below, black parts match Adafactor and blue parts are our changes.

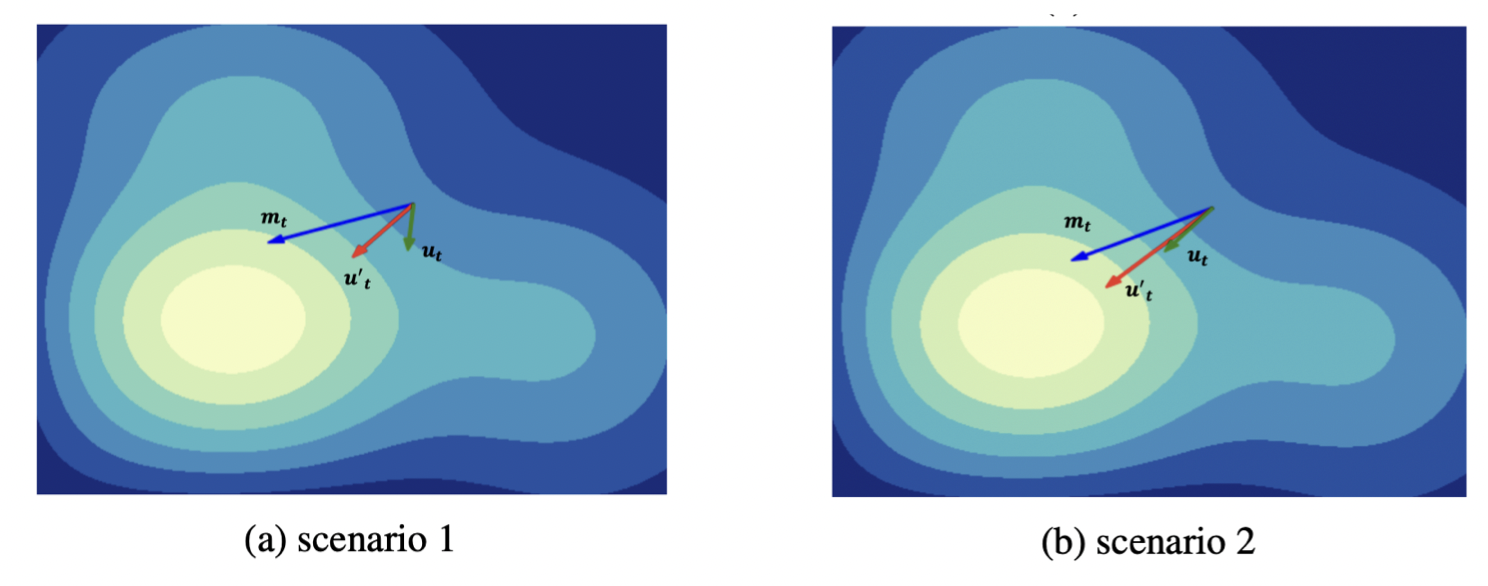
The key difference is the confidence matrix , which adjusts the update magnitude. The idea is simple: Adafactor’s approximation can cause update errors. Momentum (already used by Adafactor) smooths updates, and CAME goes further by down-weighting updates that deviate a lot from the momentum and allowing those closer to momentum to pass through. The figure below shows the effect.
Experiments
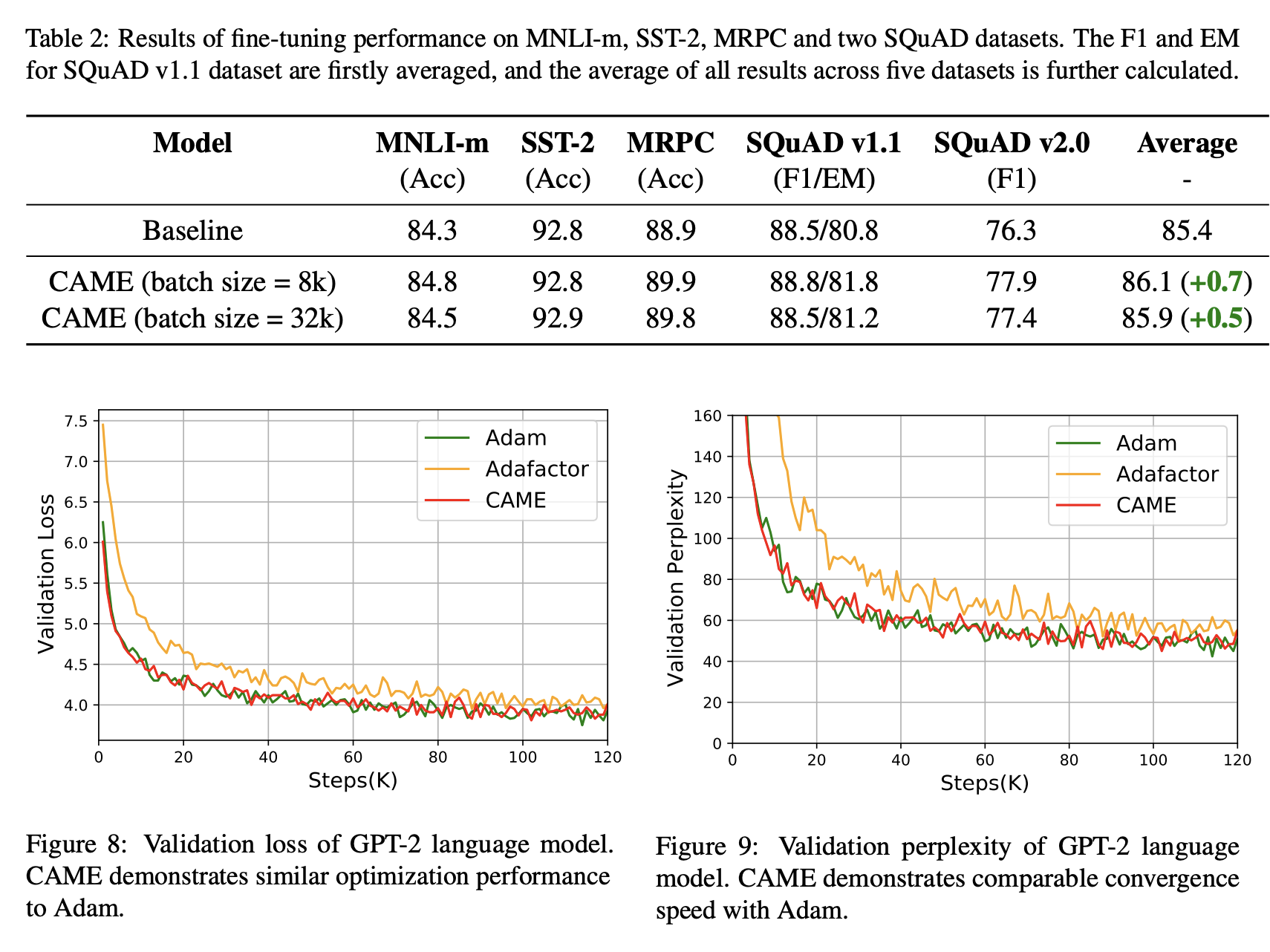
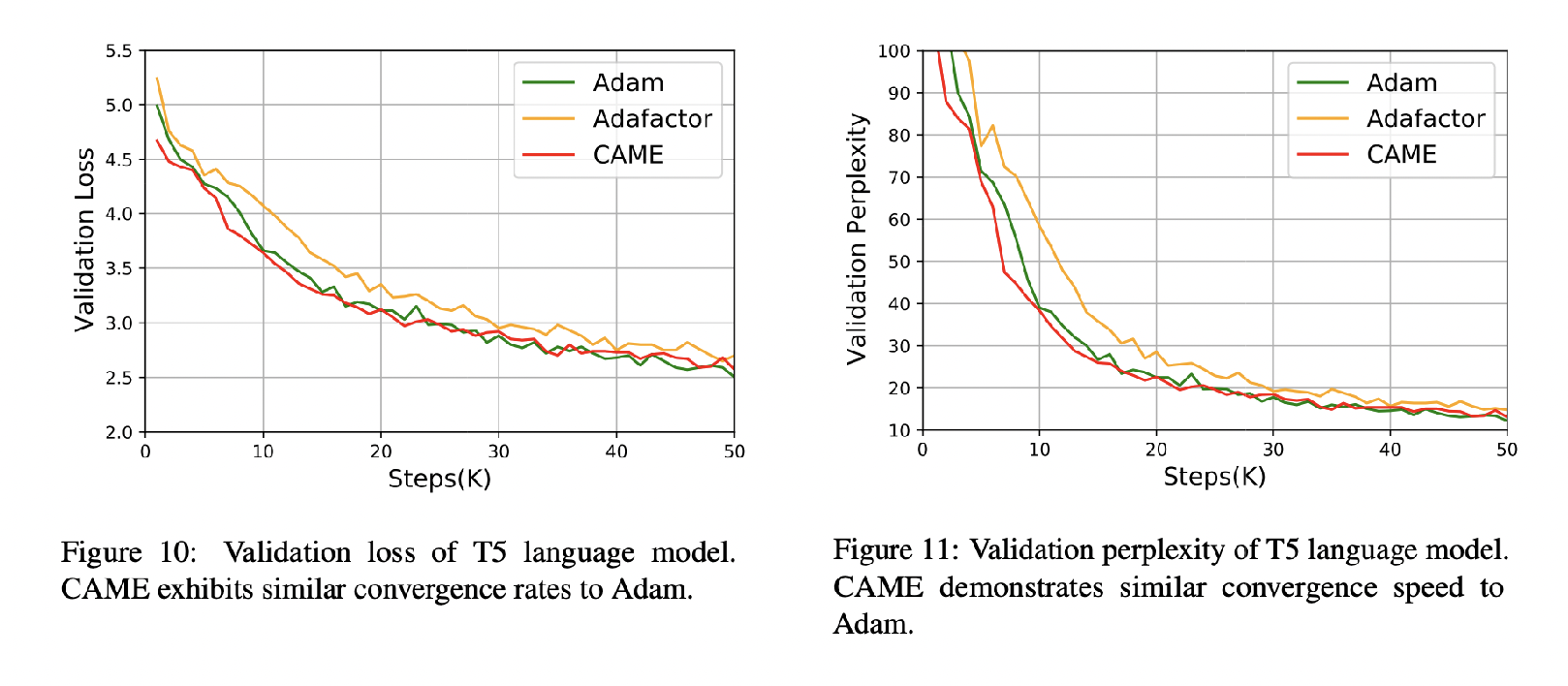
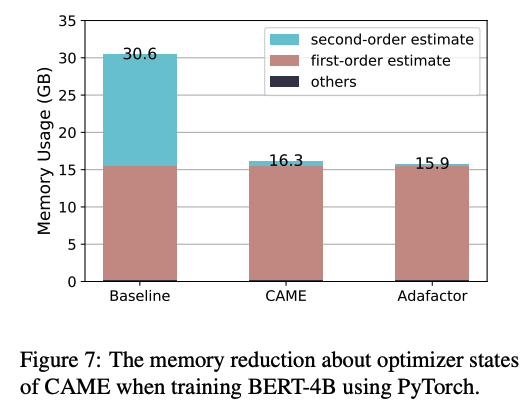
We test CAME on common large-scale pretraining tasks, including BERT and T5. CAME beats Adafactor and matches or surpasses Adam, while using memory similar to Adafactor. It is also more robust for very large batch sizes.
Future work
We are building a plug‑and‑play optimizer library that drops into existing training pipelines, including models like GPT‑3 and LLaMA. We are also exploring removing the momentum state in both Adafactor and CAME to simplify them further.
As GPU clusters scale up, we are studying how CAME performs with even larger batch sizes to further leverage its memory savings and stability.
Overall, our goal is to provide practical, memory‑efficient, and high‑performance optimization for LLM training.