Zangwei Zheng, zangwei@u.nus.edu
National University of Singapore
ICCV 2023
Other version: [arXiv] [Code] [中文]
Discuss on X with the author.
TL;DR
Large vision‑language models (VLMs) can solve new tasks in a zero‑shot way. But when we keep fine‑tuning them on new tasks, their zero‑shot ability on other datasets often drops. ZSCL is a simple fix: we add constraints in the feature space and in the parameter space so the model learns the new task while keeping its zero‑shot transfer. It improves downstream performance and preserves zero‑shot ability.
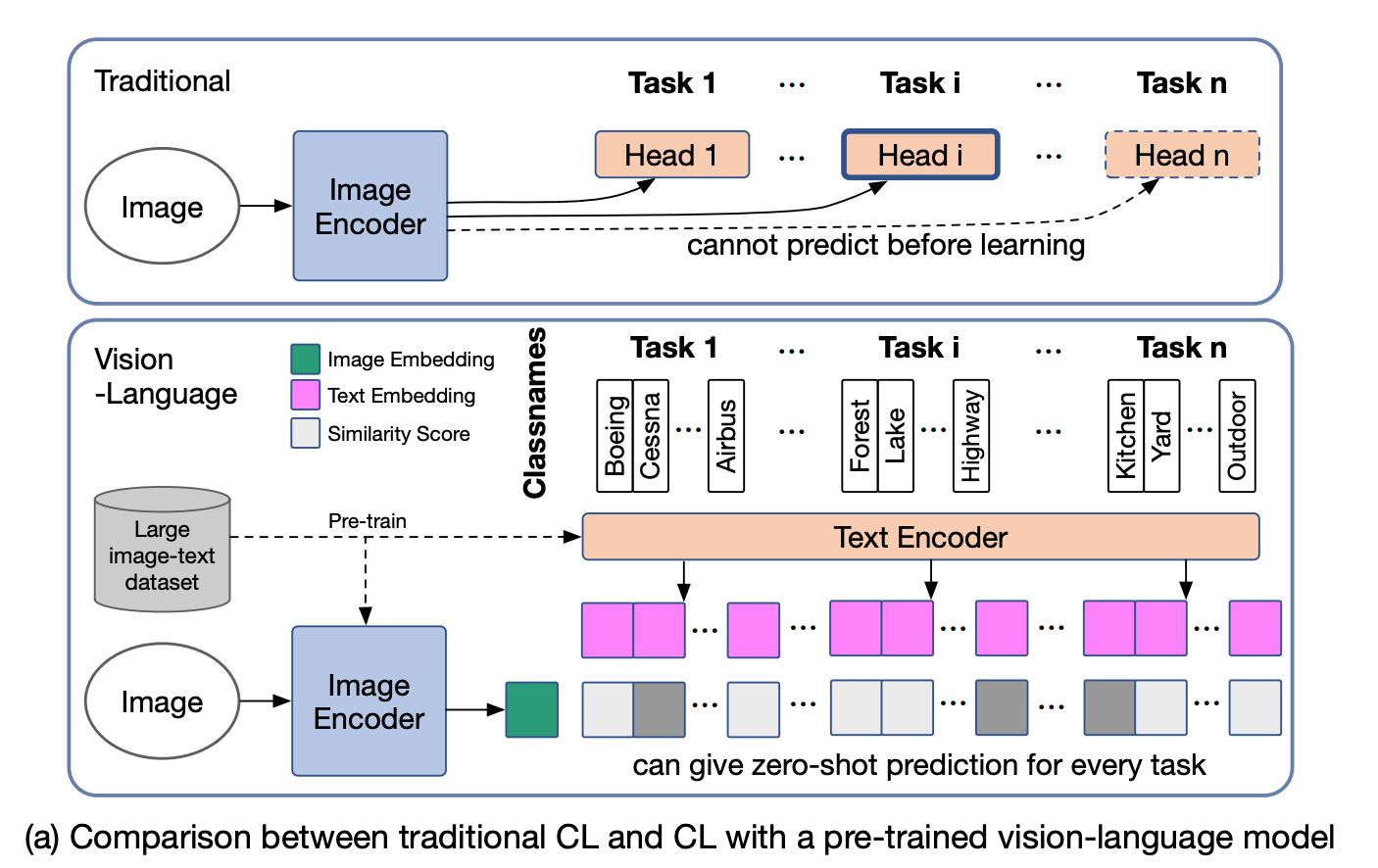
Catastrophic forgetting when fine‑tuning VLMs
Catastrophic forgetting happens when a model trained on a new task loses performance on older tasks. Pretrained vision‑language models have the same issue for zero‑shot transfer. To study and measure this, we build a benchmark called Multi‑domain Task Incremental Learning (MTIL). It covers eleven domains with very different semantics. Some examples are shown below.

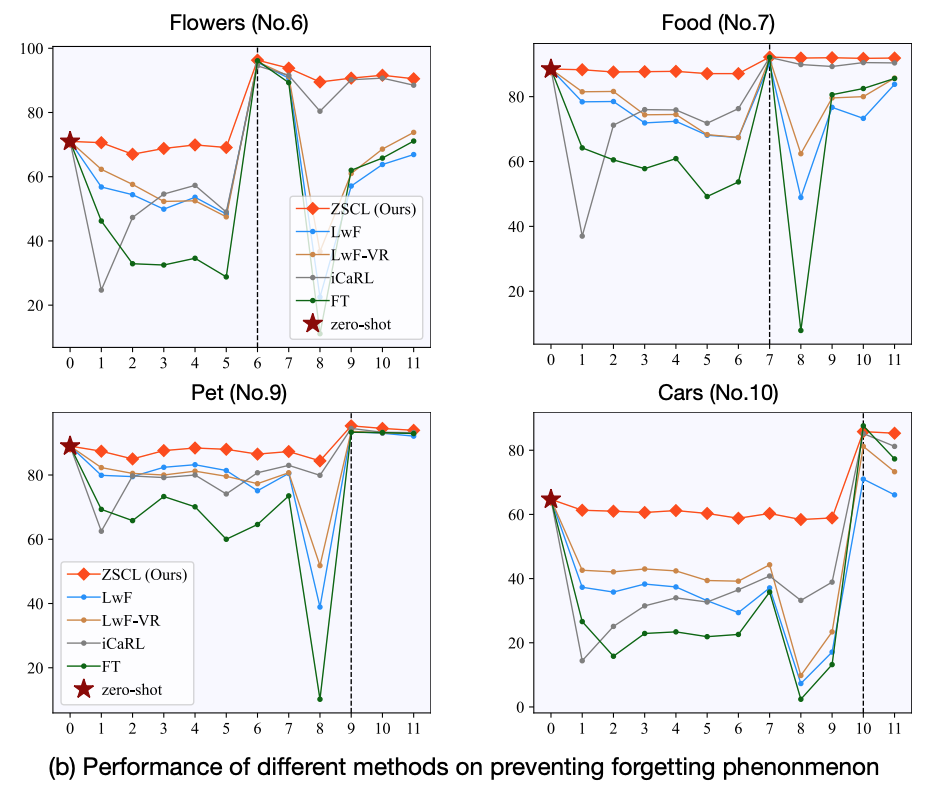
When we train a pretrained VLM like CLIP on tasks one by one, zero‑shot performance on other datasets drops a lot. The figure below shows four domains during training across eleven domains. Before each domain is fine‑tuned, its zero‑shot accuracy has already fallen (green line). Prior methods reduce the drop a bit, but the decrease is still large. Our method (red line) keeps the zero‑shot performance much better.
Constraints in feature space and parameter space
You can think of a pretrained VLM’s knowledge as living in two places: the feature space (the final layer outputs) and the parameter space (the weights). To fight catastrophic forgetting, we add constraints in both spaces.
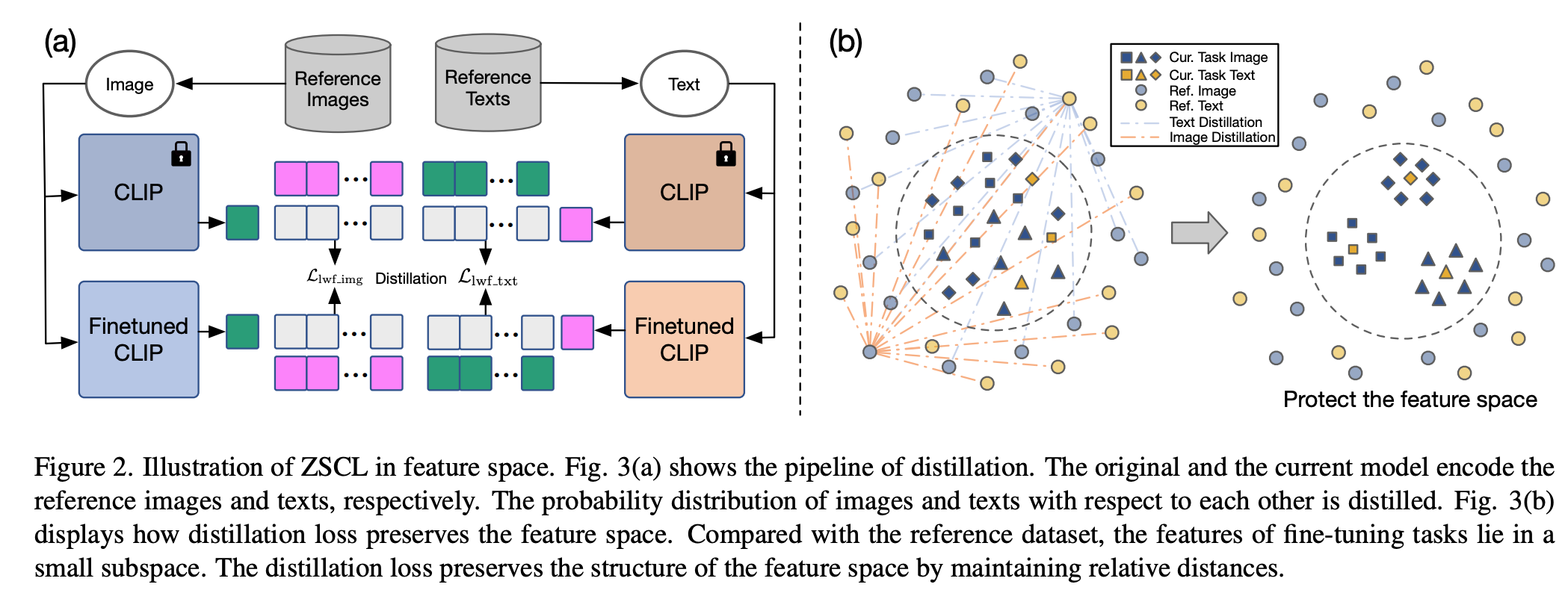
In the feature space, we use an LwF‑style loss to make the model’s output resemble the pretrained model. The loss is:
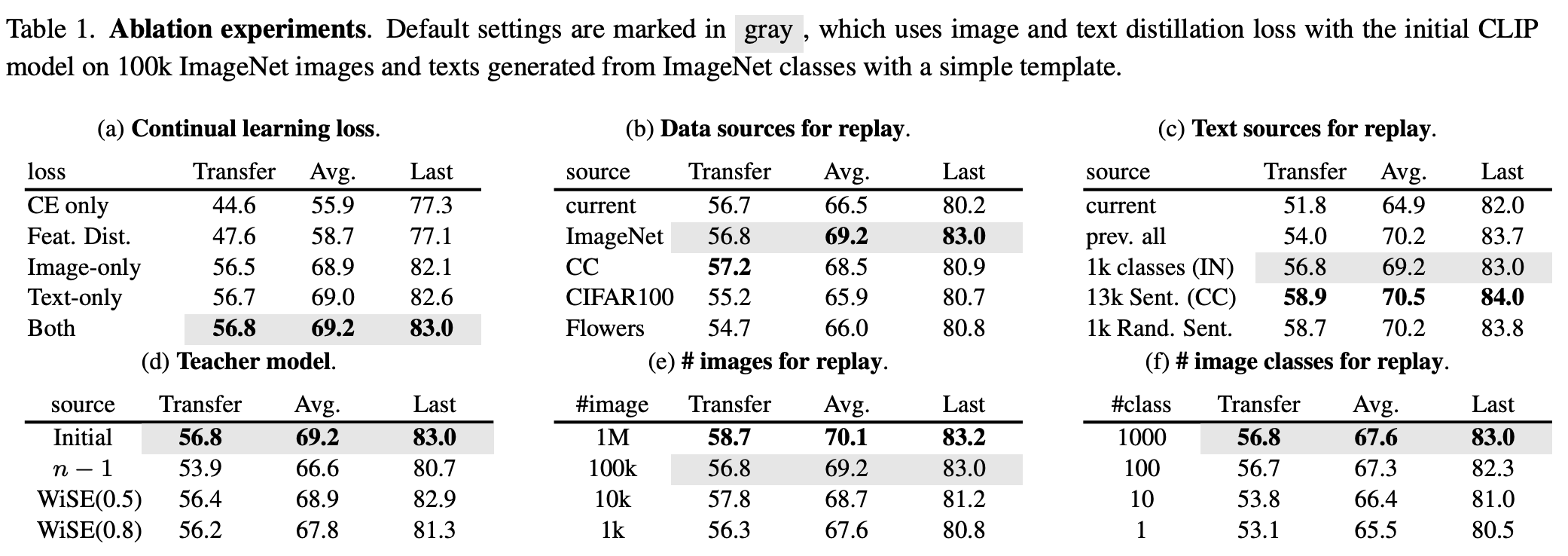
It is applied to both text and image parts. Our key change from LwF is adding a reference dataset and a reference model. The reference dataset only needs diverse semantics; it does not have to be labeled, pretrained, or contain matched image‑text pairs. The reference model is the pretrained model itself (not the previous‑task model as in LwF). See the figure for ablations.
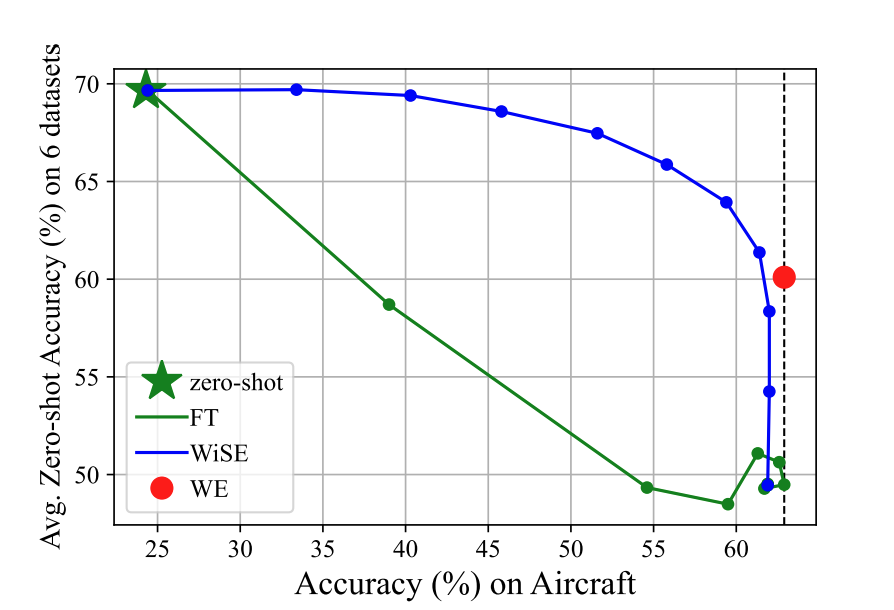
In the parameter space, we take inspiration from WiSE‑FT, which mixes the fine‑tuned and pretrained models to balance zero‑shot and task performance. We notice that checkpoints during training represent different trade‑offs, so we can ensemble them to better keep parameter knowledge. The update looks like Stochastic Weight Averaging (SWA):
Results
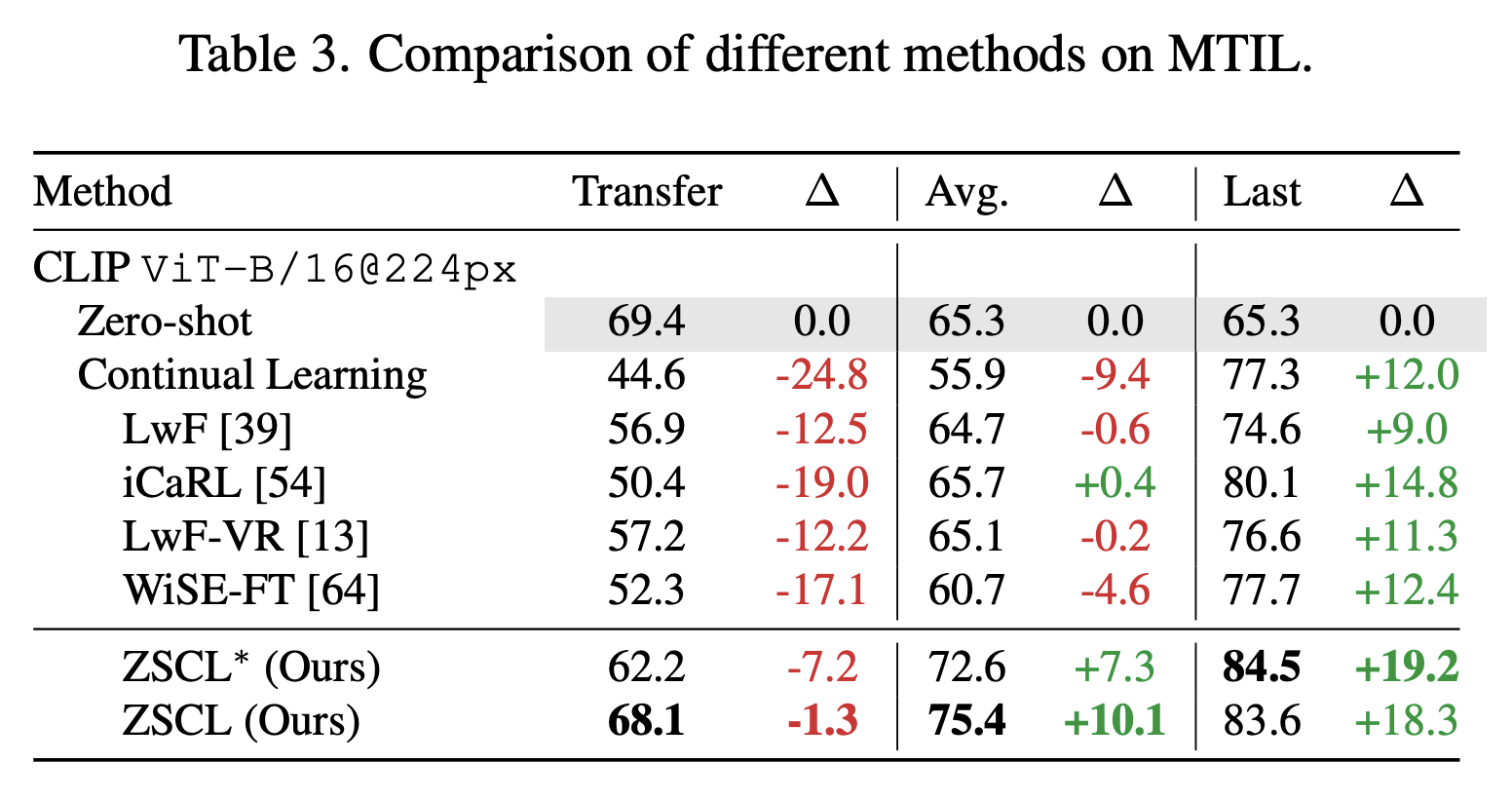
We evaluate ZSCL on MTIL and on standard continual learning datasets. Here we show MTIL results. In MTIL, Transfer measures performance on unseen datasets, and Last is the final performance after all steps. ZSCL greatly boosts Last with only a small drop in Transfer, so it improves overall performance while keeping transfer ability.
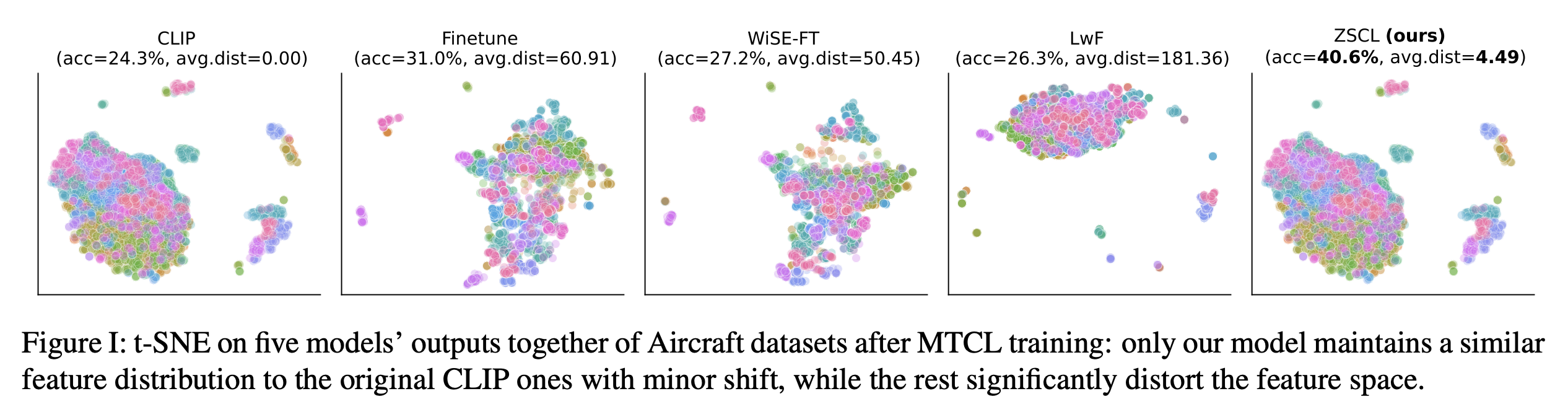
We also visualize the feature space on the Aircraft dataset after MTIL. We collect features from five model outputs and run t‑SNE. The plot shows our method preserves the pretrained model’s feature space—almost identical to the original—so important features are kept through the MTIL process.
Discussion
With today’s large models, training from scratch for continual learning is less practical, but fine‑tuning pretrained models on new tasks is still crucial—for adding new knowledge or fixing mistakes. Continual learning is far more efficient than re‑collecting data and retraining. Our work targets the zero‑shot transfer drop during this process and evaluates ZSCL on CLIP. As multimodal models like MiniGPT‑4 and LLaVA grow, applying ZSCL to them is a promising direction.