本文由 AI 自动从英文版翻译
Zangwei Zheng, zangwei@u.nus.edu
新加坡国立大学
ACL 2023 杰出论文奖
其他版本:[arXiv] [Code] [中文]
在 X 上与作者讨论。
摘要
训练大语言模型(LLM)需要大量内存。CAME 将内存使用降低到 Adafactor 水平,同时保持类似 Adam 的性能。
LLM 训练需要大量内存
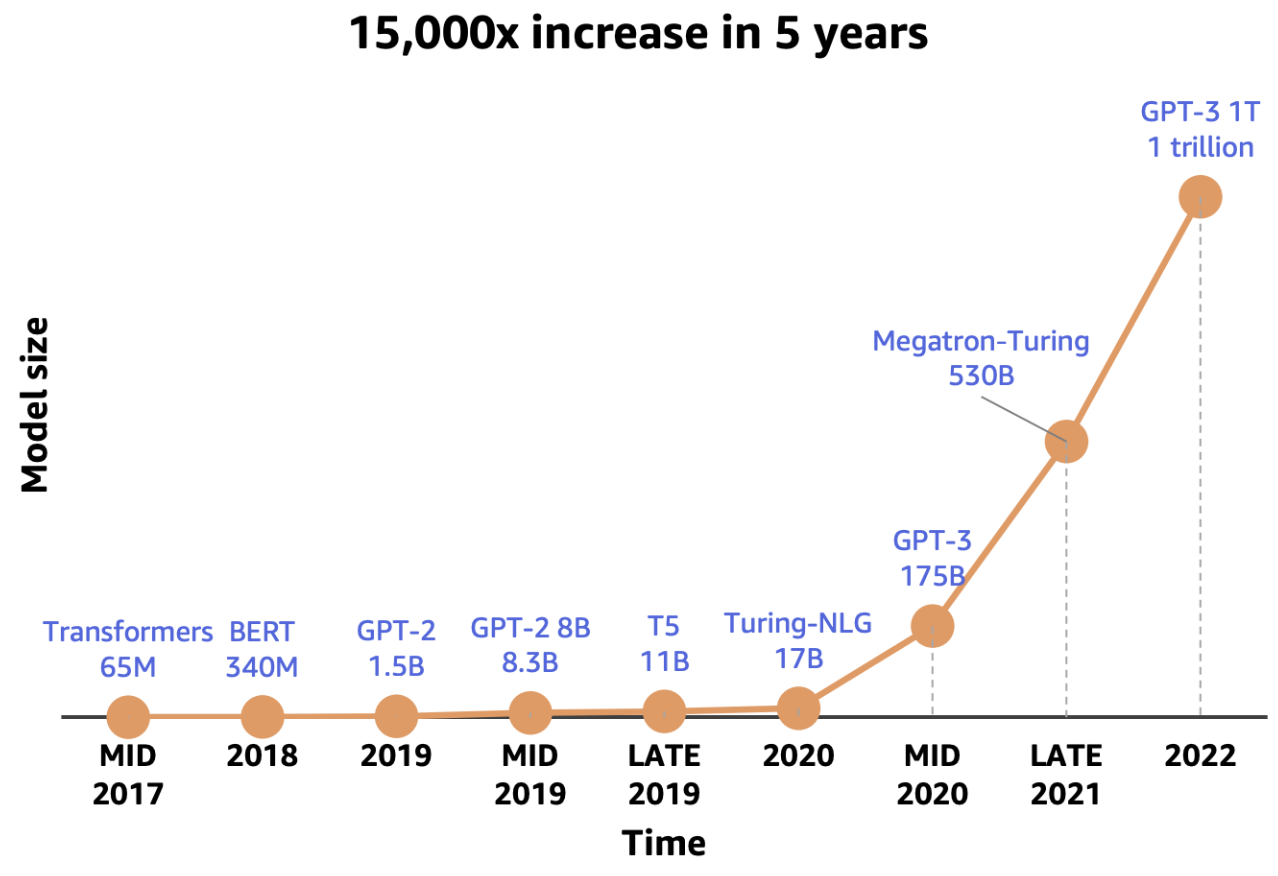
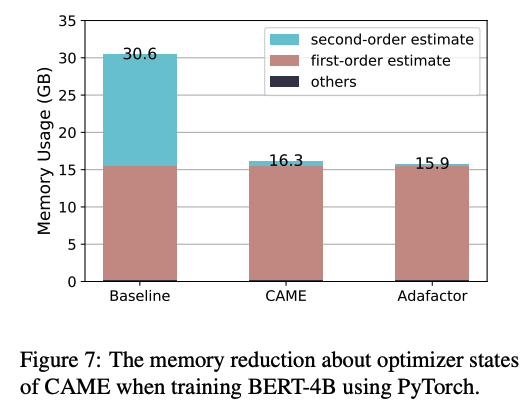
随着 LLM 的增长,训练它们需要更多内存。大部分内存用于优化器,而不仅仅是模型权重。例如,Adam 在混合精度训练中需要大约六倍于模型本身的内存,因为它存储 m 和 v 状态以及 fp32 副本。
节省内存的一种方法是缩小优化器状态。Adafactor 在 Google 广泛使用,它通过分解二阶矩状态 v 来实现这一点:
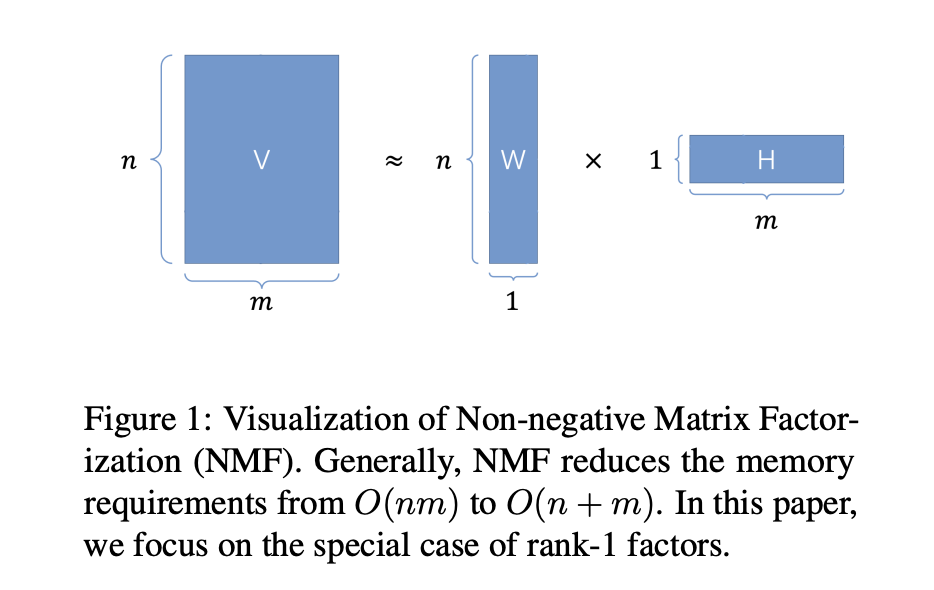
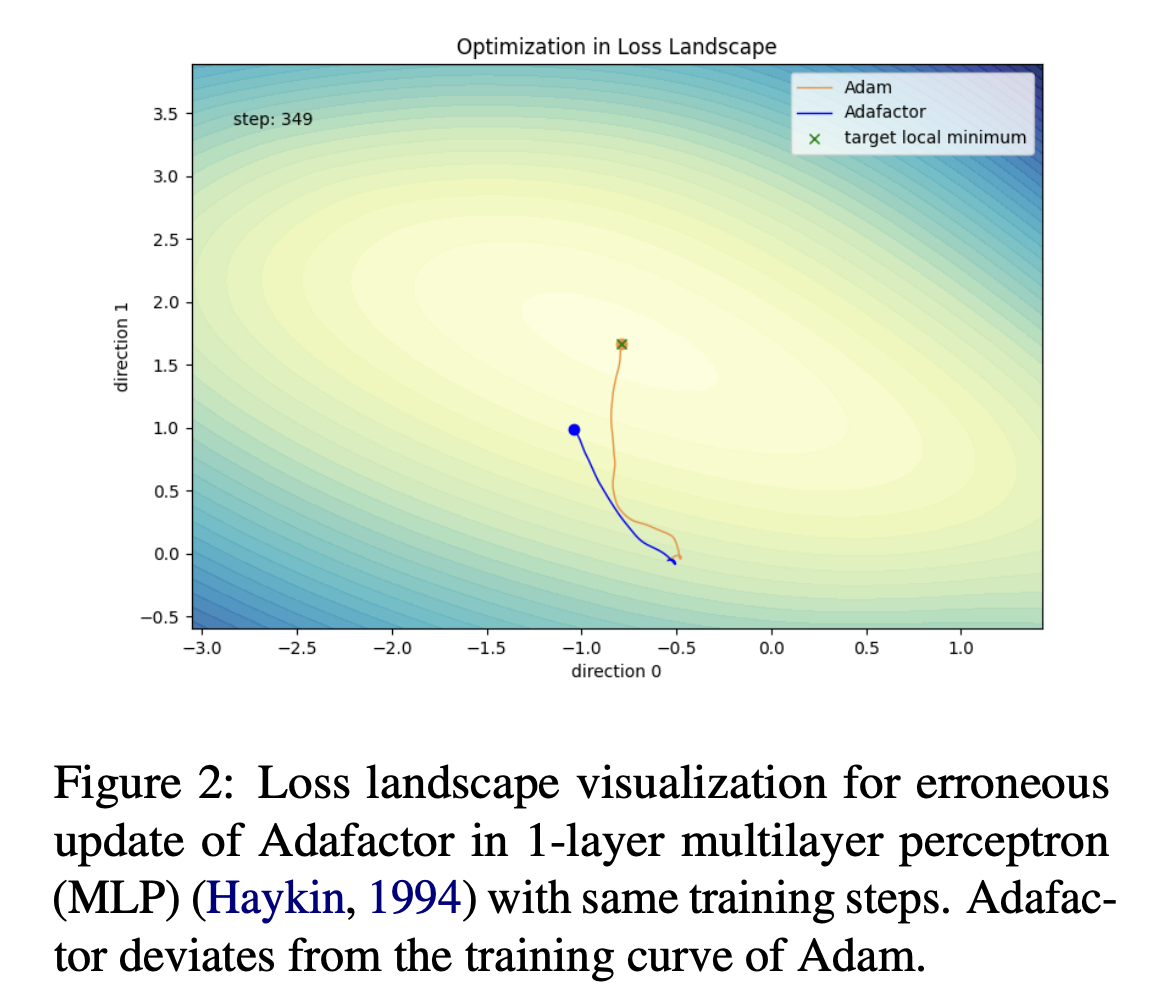
这将内存从 O(nm) 减少到 O(n+m),成本要低得多。然而,分解可能使更新不稳定,并损害大规模预训练的性能。在一个简单的 1 层 MLP 示例中,Adafactor 偏离了 Adam 的训练曲线。
置信度引导的自适应内存高效优化(CAME)
为了修复 Adafactor 的不稳定性,我们提出了 CAME。CAME 对更新大小添加基于置信度的校正,然后使用非负矩阵分解对置信度矩阵进行分解,因此它不会增加太多内存。在下面的算法中,黑色部分与 Adafactor 匹配,蓝色部分是我们的更改。

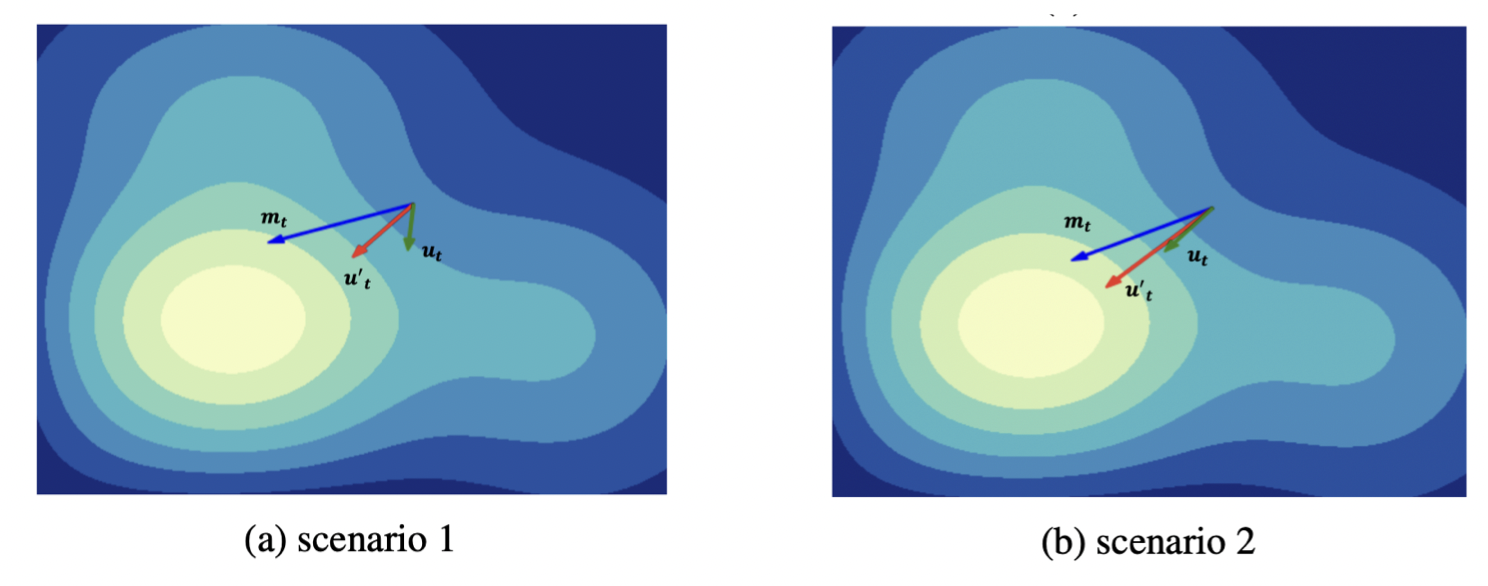
关键区别是置信度矩阵 ,它调整更新幅度。这个想法很简单:Adafactor 的近似可能导致更新错误。动量(Adafactor 已经使用)平滑更新,CAME 通过降低偏离动量很多的更新的权重,并允许更接近动量的更新通过,进一步改进。下图显示了效果。
实验
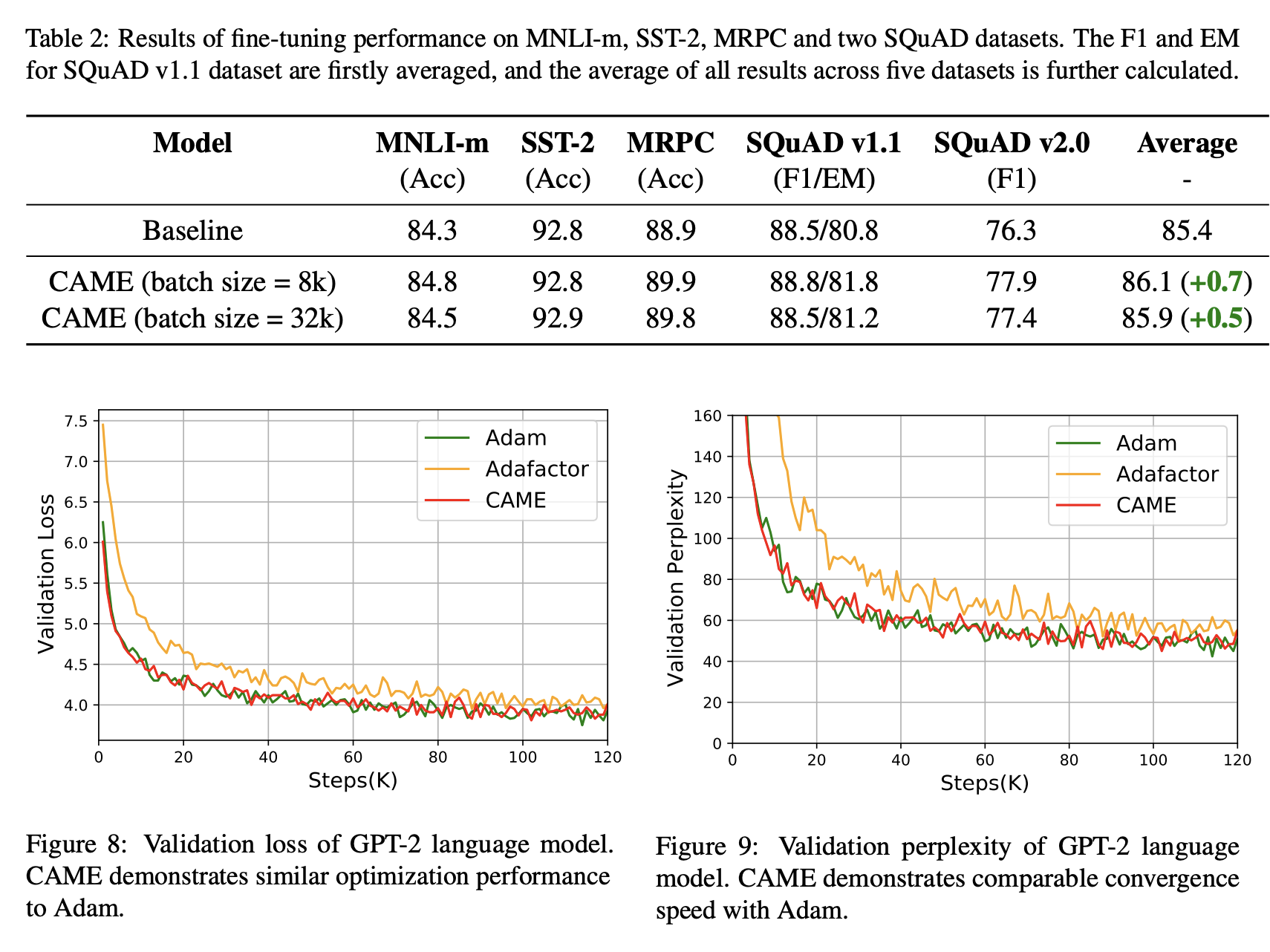
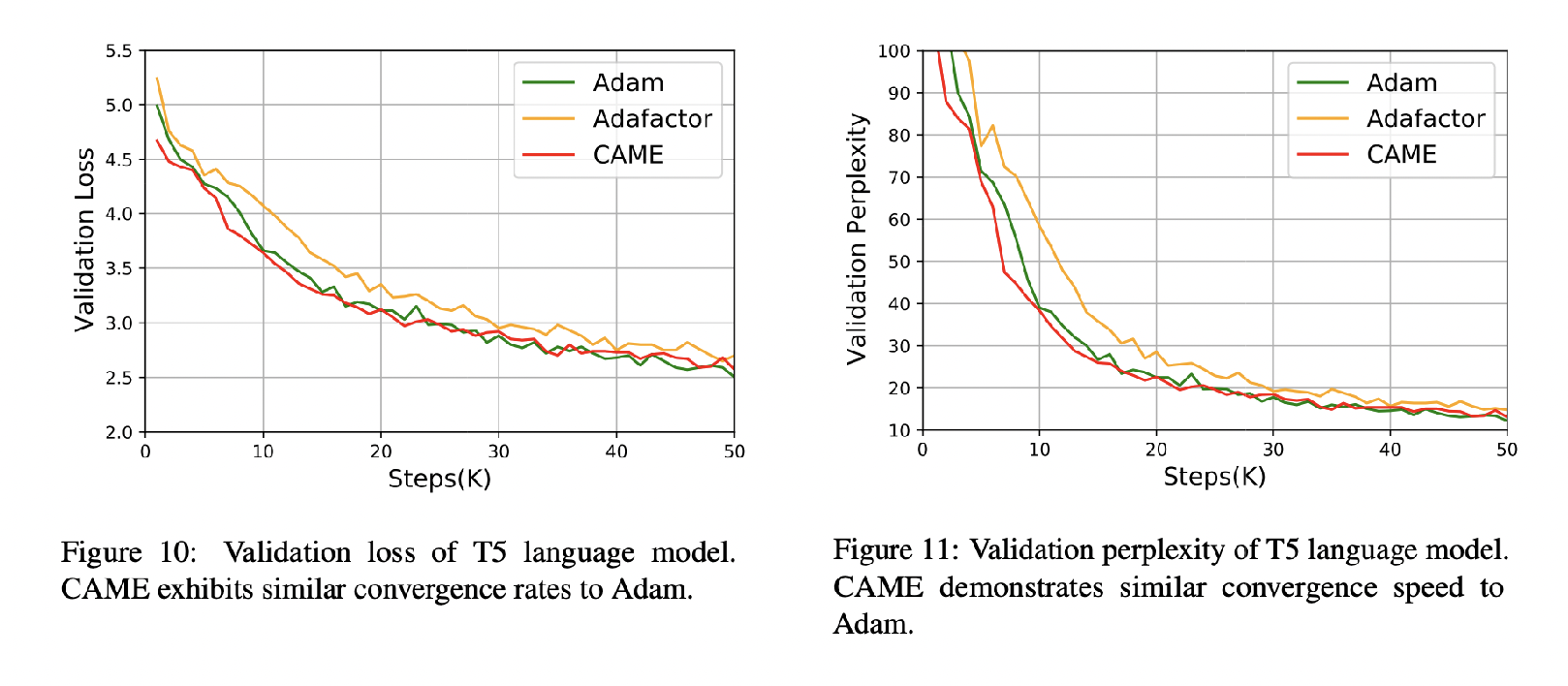
我们在常见的大规模预训练任务上测试 CAME,包括 BERT 和 T5。CAME 击败了 Adafactor,并匹配或超越了 Adam,同时使用与 Adafactor 相似的内存。对于非常大的批量大小,它也更加稳健。
未来工作
我们正在构建一个即插即用的优化器库,可以轻松集成到现有的训练管道中,包括 GPT-3 和 LLaMA 等模型。我们还在探索移除 Adafactor 和 CAME 中的动量状态,以进一步简化它们。
随着 GPU 集群的扩展,我们正在研究 CAME 在更大批量大小下的表现,以进一步利用其内存节省和稳定性。
总的来说,我们的目标是为 LLM 训练提供实用、内存高效且高性能的优化。