本文由 AI 自动从英文版翻译
Zangwei Zheng, zangwei@u.nus.edu
新加坡国立大学
ICLR 2024 Oral
其他版本:[arXiv] [Code] [中文]
在 X 上与作者讨论。
摘要
多轮训练在简单、已学好的样本上浪费时间。InfoBatch 通过动态剪枝数据并重新缩放损失以保持性能来加速训练。它在图像分类、语义分割、视觉预训练、扩散模型和 LLM 指令微调上实现了 20-40% 的训练加速,而不会损失准确性。
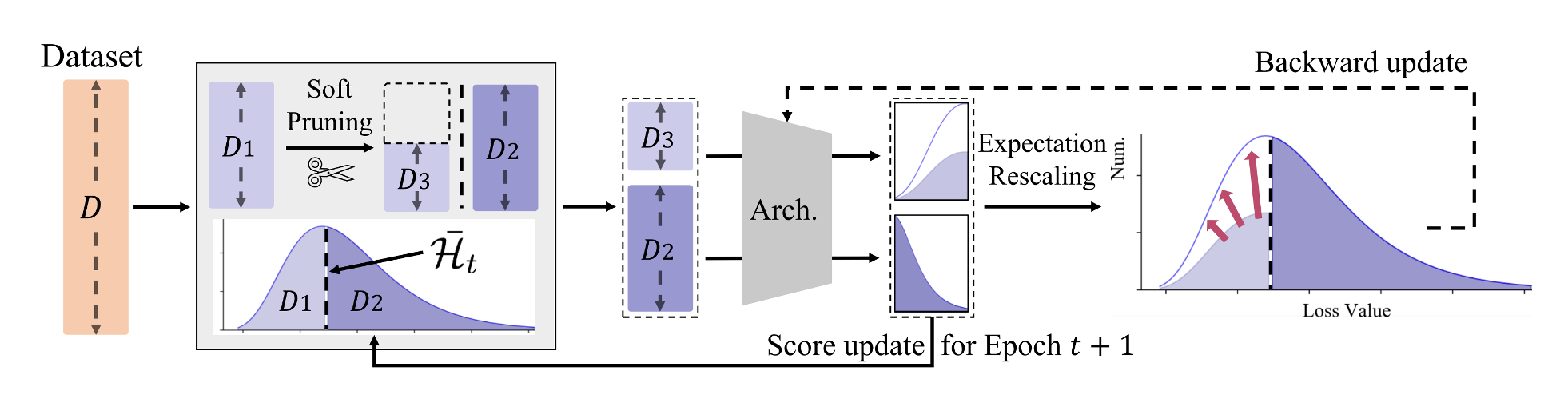
InfoBatch 如何工作?
我们为 InfoBatch 提供了一个即插即用的 PyTorch 实现(正在积极开发中)。通过下面显示的三个更改,你可以将 InfoBatch 插入到你的训练代码中。

以下是 InfoBatch 算法的简要概述。
- 首先,InfoBatch 随机丢弃损失低于批次平均损失的一部分 样本。论文讨论了更高级的策略,但这个简单的规则已经非常有效。
- 其次,对于剩余的低于平均损失的样本,InfoBatch 将其损失重新缩放为 ,以保持整体训练无偏。
- 第三,在训练结束时,InfoBatch 遍历所有样本一次以减轻遗忘。
超参数 控制执行动态剪枝的轮次比例。一个好的起点是 。
在上面的代码中:(1) 数据集被包装并管理索引顺序,(2) InfoBatch 采样器被传递给 DataLoader 构造函数,以及 (3) 在前向和反向传播之间重新缩放损失并使用损失更新采样器。有关更多数学讨论和消融实验,请参阅论文。对于并行训练,请参阅代码。
应用
InfoBatch 背后的想法简单但在许多应用中有效。
- 图像分类:40% 加速,无准确性下降,与先前方法不同。
- MAE 预训练:ViT 和 Swin 节省 20% 时间,无下游准确性损失。
- 语义分割:节省 40% 时间,无 mIoU 下降。
- 扩散模型:节省 27% 时间,FID 相当。
- LLM 指令微调:节省 20% 时间。