本文由 AI 自动从英文版翻译
Zangwei Zheng, zangwei@u.nus.edu
新加坡国立大学
其他版本:[arXiv] [Github] [中文]
在 X 上与作者讨论。
摘要
我们发现大语言模型(LLM)具有预测其生成响应长度的非凡能力。通过利用这种能力,我们提出了一种称为序列调度的新技术来提高 LLM 批量推理的效率。通过将具有相似预期响应长度的查询分组在一起,我们显著减少了冗余计算,并在不损害性能的情况下实现了令人印象深刻的 86% 推理吞吐量提升。
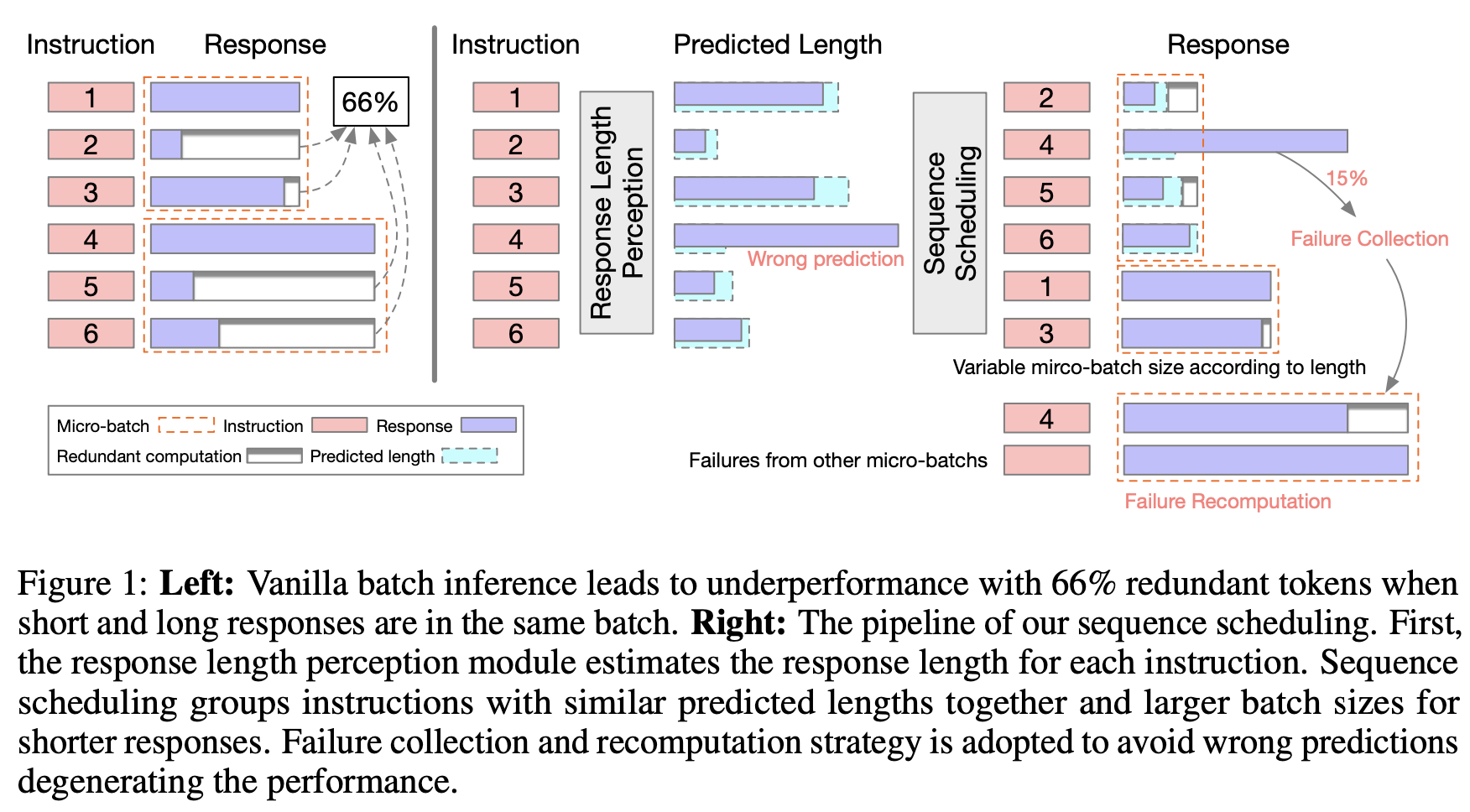
LLM 知道其响应长度
我们通过检查 LLM 是否具有预测其生成响应长度的能力来开始我们的研究。为了探索这种能力,我们设计了一种称为"提前感知(PiA)"的提示技术,要求模型预测其生成响应的长度。
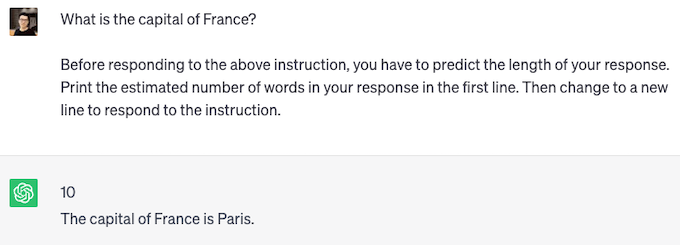
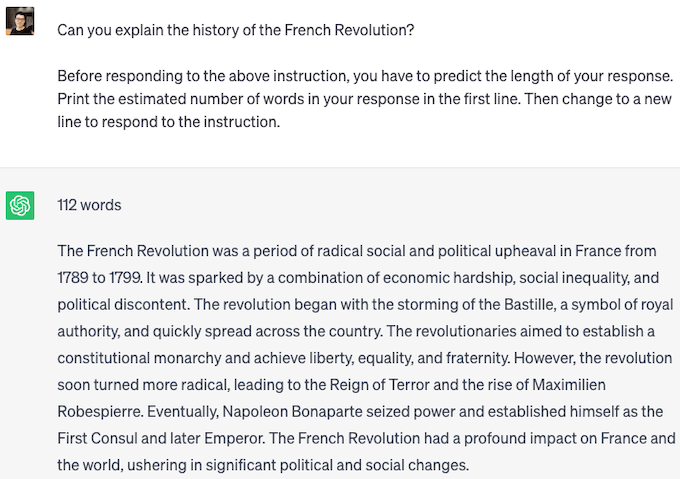
我们发现流行的 LLM(如 GPT-4、ChatGPT 和 Vicuna)可以遵循指令并提供响应长度估计。上面的两个图展示了 ChatGPT 的 PiA 示例。对于短响应,ChatGPT 预测长度为 10 个单词,实际长度为 6 个单词。对于长响应,ChatGPT 预测长度为 112 个单词,实际长度为 119 个单词。尽管 ChatGPT 可能没有明确训练用于响应长度预测,但它准确估计了生成响应的长度。
指令微调改善响应长度感知
对于像 Vicuna-7B 这样的开源指令微调语言模型(LLM),准确预测响应长度仍然具有挑战性。当考虑 100 个单词范围内的估计为准确时,它在 Alpaca 数据集上仅达到 65% 的准确率。此外,LLM 对 token 的理解比对单词的理解更弱,这限制了它们提高推理效率的能力。
为了增强模型预测响应长度的能力,我们开发了一个包含指令及其对应 token 长度对的数据集。通过利用 LoRA 进行高效的指令微调,我们旨在提高其性能。作为这个微调过程的结果,模型在 Alpaca 数据集上达到了 81% 的改进准确率。
LLM 批量推理
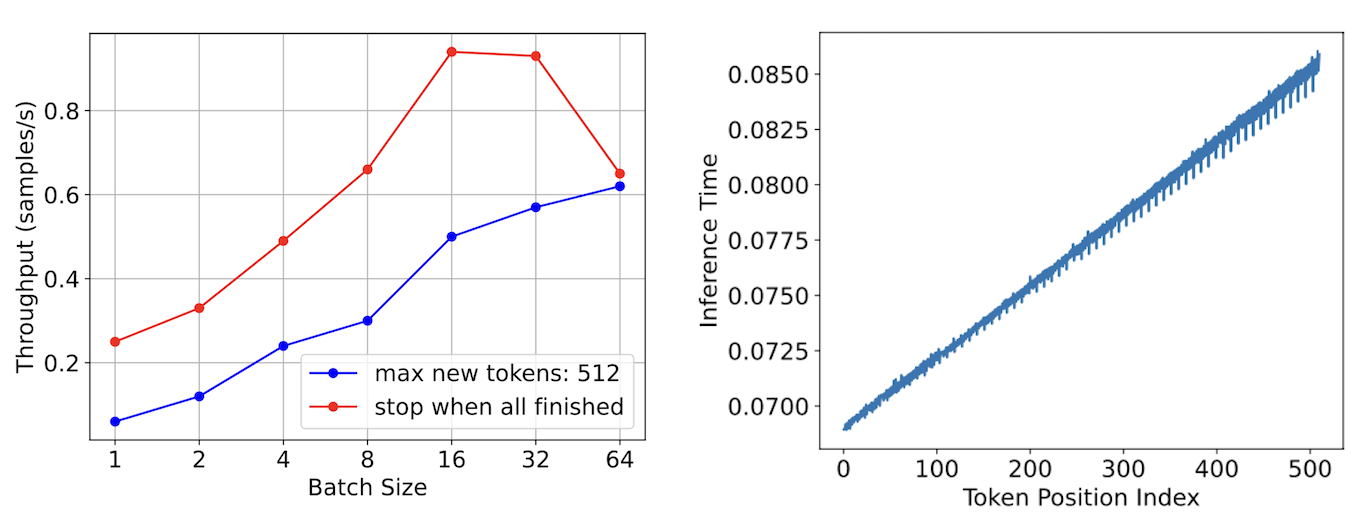
现在让我们检查 LLM 推理过程。批量推理是一种常用的提高推理效率的技术。在左图中,我们观察到随着批量大小的增加,推理吞吐量几乎线性增加(如蓝线所示)。然而,当批量执行 LLM 推理时,包含不同响应长度的序列会引入低效率。较短的序列必须等待较长的序列完成,导致效率降低。我们发现大约 66% 执行的计算是冗余的。随着批量大小继续增长,吞吐量性能开始下降(如红线所示)。这种下降发生是因为更大的批量大小更可能包含更长的响应长度,导致冗余计算显著增加。
此外,右图表明推理时间随着 token 位置索引的增加而增加。这种增加发生是因为自注意力操作必须在越来越多的键和值上执行。
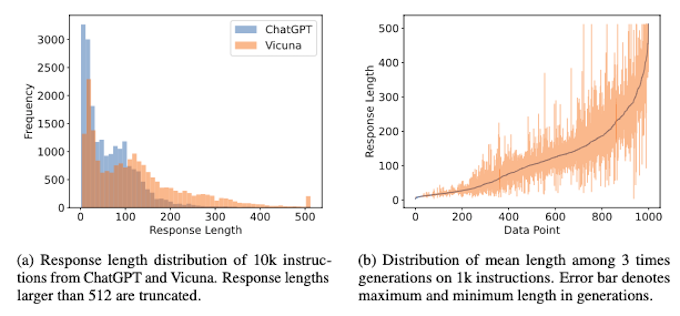
在现实场景中,查询响应长度差异很大,如 ChatGPT 和 Vicuna 模型在 Alpaca 数据集中查询的长度分布所示(图的左侧)。这突出了解决 LLM 推理中不同响应长度挑战的必要性。此外,在右侧,我们观察到同一数据点的不同采样可能导致不同的长度,这增加了预测和处理响应长度的复杂性。
通过响应长度感知进行序列调度
我们提出了一种称为序列调度的新技术来提高 LLM 批量推理的效率。通过将具有相似预期响应长度的查询组织成组,我们可以显著最小化冗余计算,从而实现了令人印象深刻的 42% 吞吐量提升。
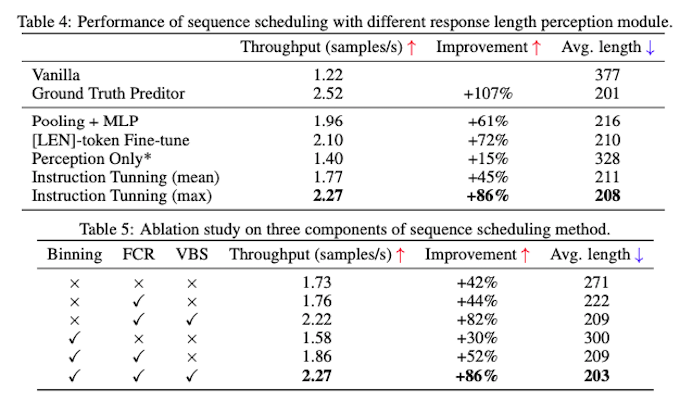
为了进一步优化吞吐量,我们引入了几个额外的技术。共同实施这些技术可以在不损害性能的情况下实现令人印象深刻的 86% 推理吞吐量提升。
- 失败收集和重新计算(FCR):我们将新生成的 token 数量限制为最多批次内最大预测长度。超过此预测长度的指令被视为失败,并在特定大小的组推理过程结束时分离出来进行重新计算。由于失败率相对较低,这种方法可以更快地生成较短的响应,同时最小化重新生成失败指令所花费的时间。
- 可变批量大小(VBS):我们为较短的响应分配更大的批量大小。这种方法允许我们同时处理更多查询,从而优化整体吞吐量。
- 最大长度预测:响应长度感知模块预测多个采样响应的最大长度。与高估相比,低估响应长度具有更严重的后果。因此,我们优先准确预测最大长度,以避免截断并确保所需的响应长度。
- 分箱:我们将具有相似响应长度的查询分组到箱中。这种方法减少了箱的数量,并实现了更高效的调度。
讨论
在这项研究中,我们利用 LLM 的能力来增强它们自己的推理过程,从而开发出我们称之为"LLM 赋能的 LLM 推理管道"的方法。这种方法可以被视为 AI 领域内的软件-硬件协同设计,我们相信它为未来的研究工作提供了巨大的前景。
我们的研究结果表明,LLM 对它们生成的响应有深刻的理解。这种洞察为开发更快的推理技术(如非自回归方法)提供了令人兴奋的机会,这些技术可以克服与顺序 token 生成相关的限制,并显著提高性能。
由于 LLM 有可能成为像搜索引擎一样普及的基础设施,它们处理的查询量预计将显著增加。此外,像 GPT-4(支持最多 32k 序列长度)和 Claude(支持 100K 序列长度)这样的模型的出现,进一步加剧了适应不同响应长度的挑战。在这种情况下,我们的方法在解决这一挑战的相关性和有效性方面脱颖而出。