本文由 AI 自动从英文版翻译
Zangwei Zheng, zangwei@u.nus.edu
新加坡国立大学
ICCV 2023
其他版本:[arXiv] [Code] [中文]
在 X 上与作者讨论。
摘要
大型视觉-语言模型(VLM)可以以零样本方式解决新任务。但当我们继续在新任务上微调它们时,它们在其他数据集上的零样本能力通常会下降。ZSCL 是一个简单的修复:我们在特征空间和参数空间中添加约束,使模型学习新任务的同时保持其零样本迁移。它提高了下游性能并保留了零样本能力。
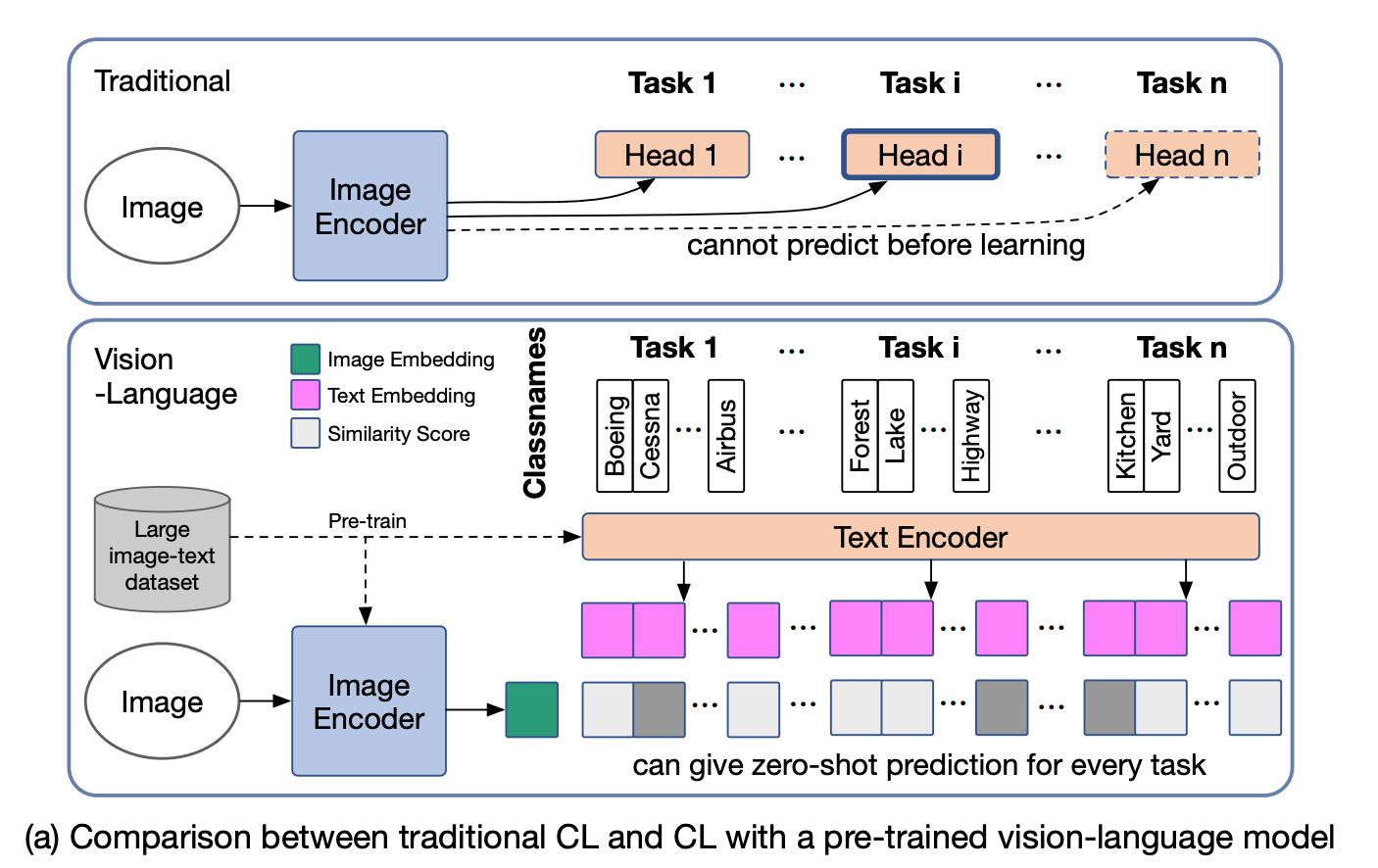
微调 VLM 时的灾难性遗忘
灾难性遗忘发生在在新任务上训练的模型在旧任务上失去性能时。预训练的视觉-语言模型对于零样本迁移也有同样的问题。为了研究和测量这一点,我们构建了一个称为多域任务增量学习(MTIL)的基准。它涵盖十一个具有非常不同语义的域。下面显示了一些示例。

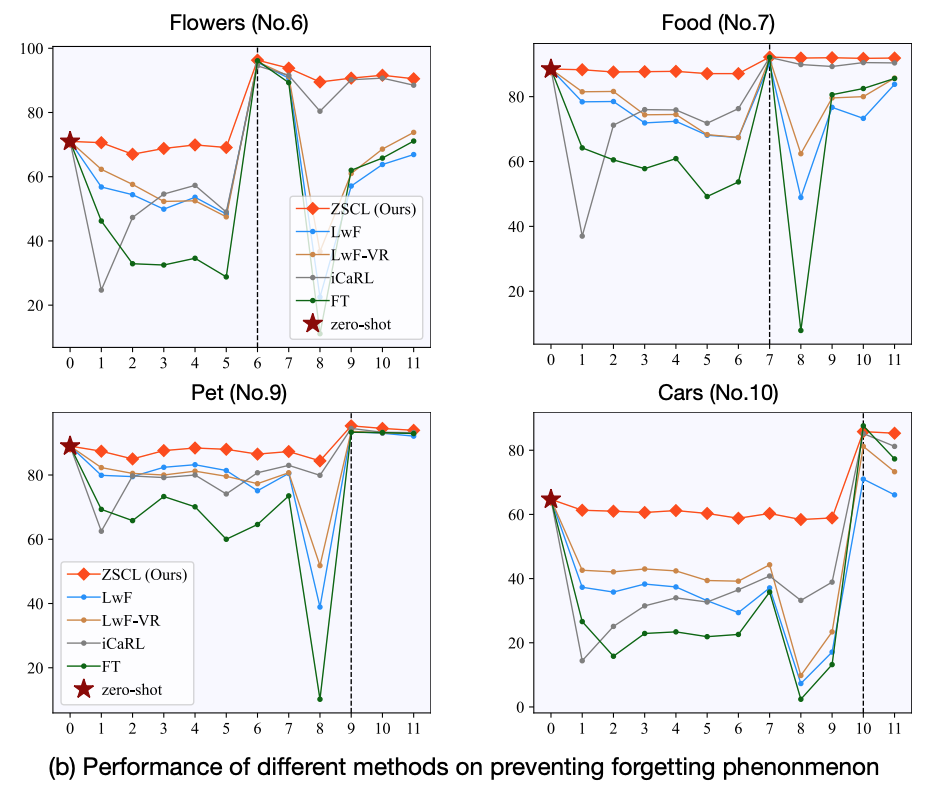
当我们逐个任务训练像 CLIP 这样的预训练 VLM 时,在其他数据集上的零样本性能下降很多。下图显示了在十一个域的训练过程中四个域的情况。在每个域被微调之前,其零样本准确性已经下降(绿线)。先前的方法稍微减少了下降,但减少仍然很大。我们的方法(红线)更好地保持了零样本性能。
特征空间和参数空间中的约束
你可以将预训练 VLM 的知识视为存在于两个地方:特征空间(最终层输出)和参数空间(权重)。为了对抗灾难性遗忘,我们在两个空间中都添加约束。
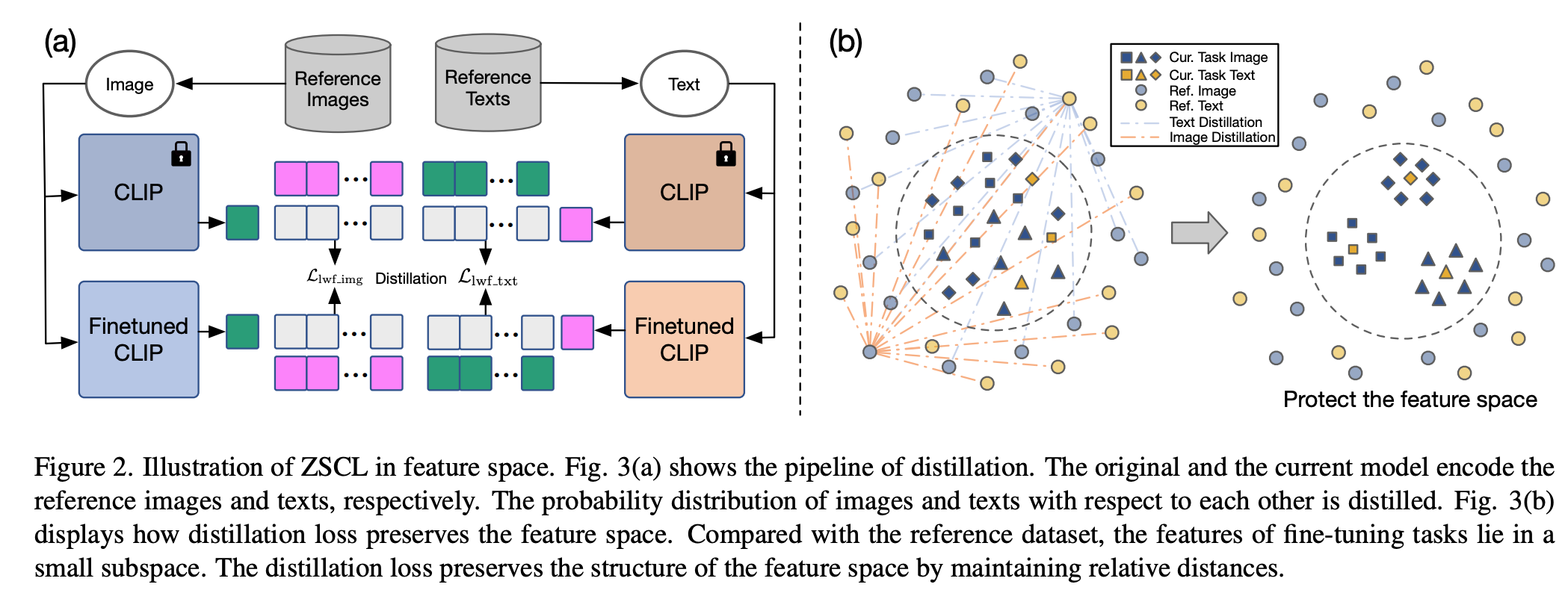
在特征空间中,我们使用 LwF 风格的损失使模型的输出类似于预训练模型。损失是:
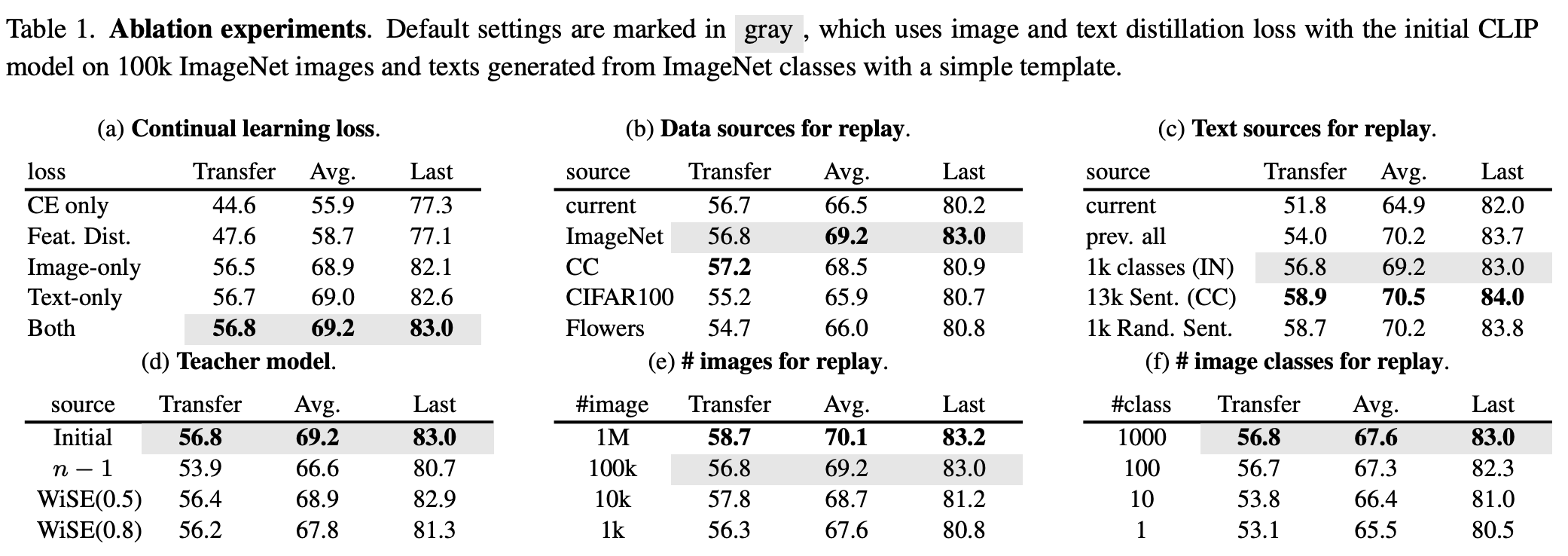
它应用于文本和图像部分。我们与 LwF 的关键区别是添加了参考数据集和参考模型。参考数据集只需要多样化的语义;它不必被标记、预训练或包含匹配的图像-文本对。参考模型是预训练模型本身(不是 LwF 中的先前任务模型)。有关消融实验,请参见图。
在参数空间中,我们受到 WiSE-FT 的启发,它混合微调和预训练模型以平衡零样本和任务性能。我们注意到训练期间的检查点代表不同的权衡,因此我们可以集成它们以更好地保持参数知识。更新看起来像随机权重平均(SWA):
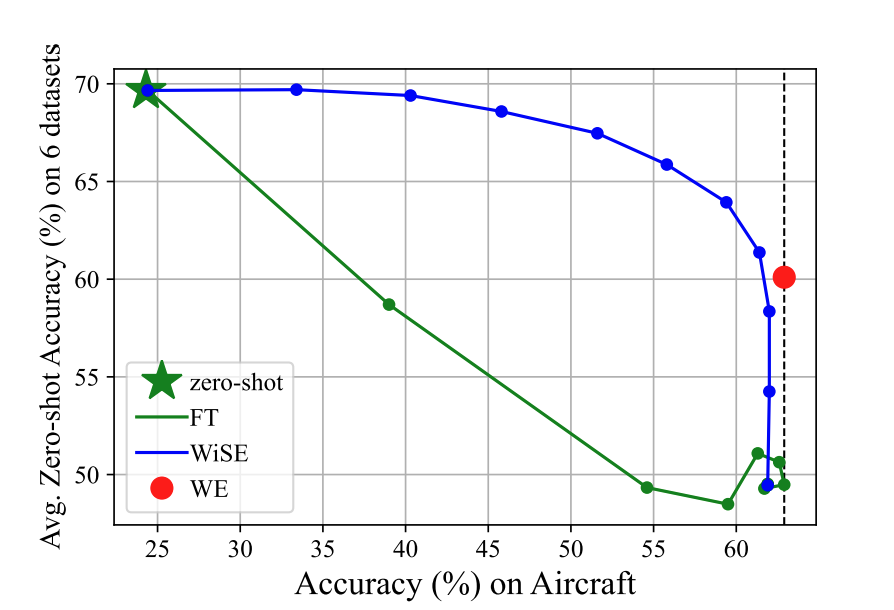
结果
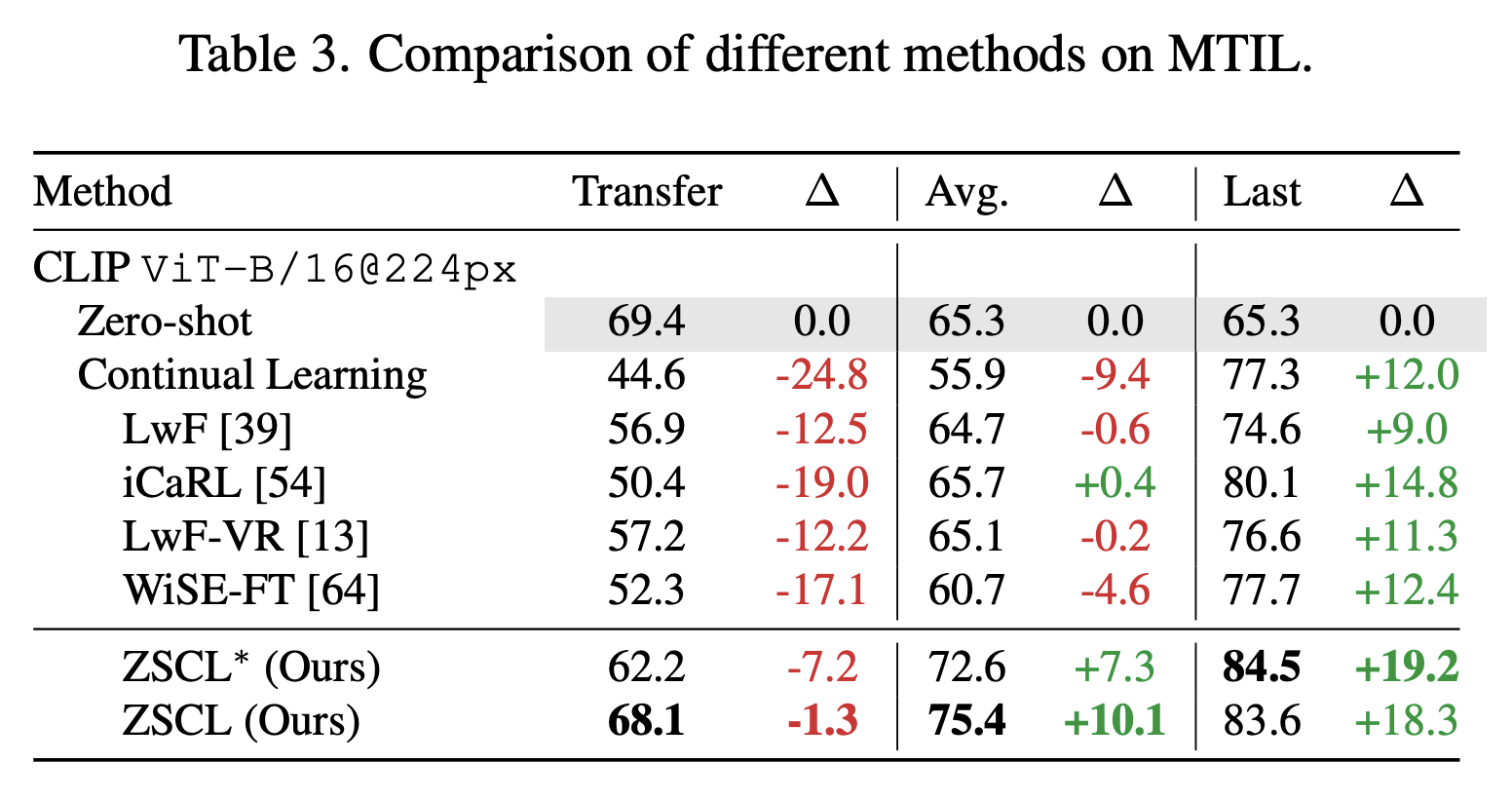
我们在 MTIL 和标准持续学习数据集上评估 ZSCL。这里我们展示 MTIL 结果。在 MTIL 中,Transfer 测量未见数据集上的性能,Last 是所有步骤后的最终性能。ZSCL 大大提高了 Last,而 Transfer 只有小幅下降,因此它在保持迁移能力的同时提高了整体性能。
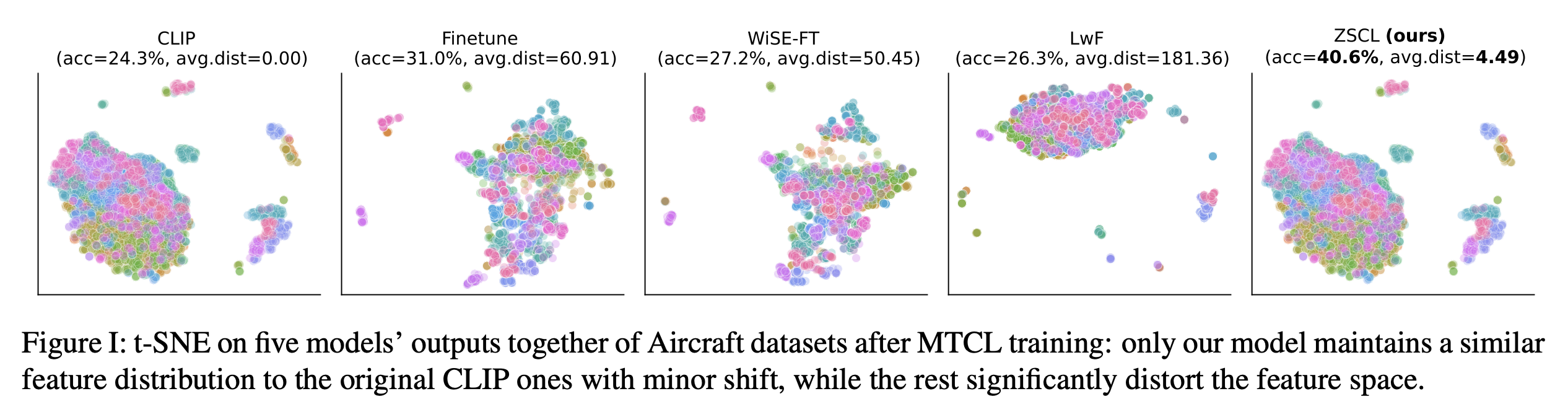
我们还在 MTIL 后在 Aircraft 数据集上可视化特征空间。我们从五个模型输出中收集特征并运行 t-SNE。该图显示我们的方法保留了预训练模型的特征空间——几乎与原始相同——因此重要特征在 MTIL 过程中得以保留。
讨论
对于今天的大型模型,从头开始训练进行持续学习不太实用,但在新任务上微调预训练模型仍然至关重要——用于添加新知识或修复错误。持续学习比重新收集数据和重新训练要高效得多。我们的工作针对此过程中的零样本迁移下降,并在 CLIP 上评估 ZSCL。随着像 MiniGPT-4 和 LLaVA 这样的多模态模型的增长,将 ZSCL 应用于它们是一个有前景的方向。